
Data Science Internships- In the present day, it is not uncommon for companies to leverage their vast reserves of data to derive business value and better strategic performance. To achieve these goals, a strong set of data scientist skills is very important.
Tech mistake | Equally important – if not more so – is proper management of the data infrastructure. Doing this requires the data to be:
-
Stored such that it can be accessed conveniently
-
Cleaned up properly
-
Kept up to date
Does a data architect earn more than a data scientist?
It is hard to say if a data architect is more important than a data science professional. The rising importance of the former, however, has meant that salaries for data architects are equally high or sometimes are even higher. According to PayScale, the average annual salary in the US for a data scientist is USD 96,089, while for a data architect it is USD 121,816.
What are the important components of a data architecture?
Below are the key components of the data architecture at a company. These handle different functionalities, as explained here:
-
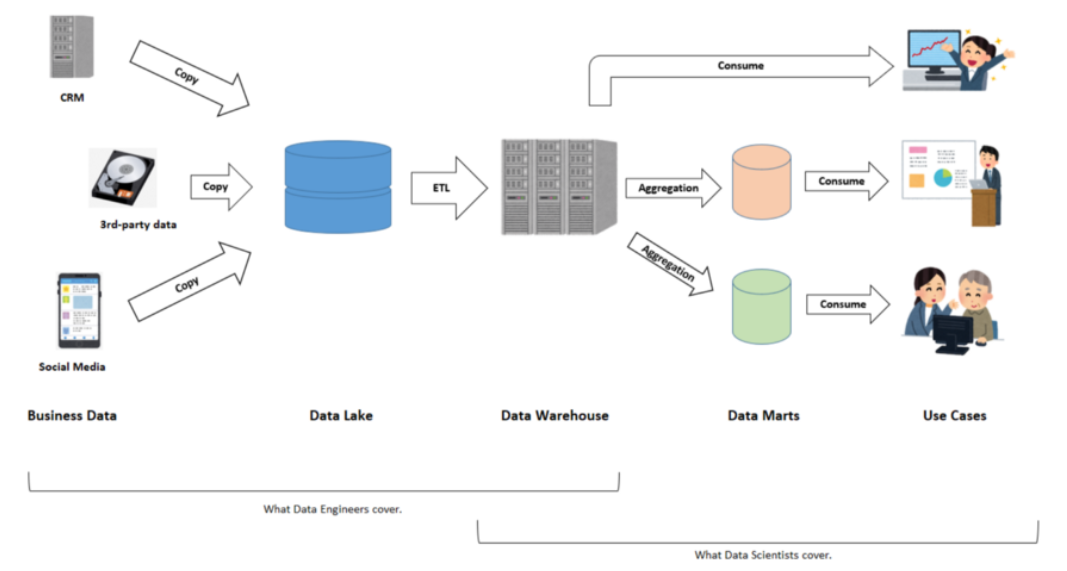
Data lake: A data lake is where the original set of business data is stored. This data should ideally undergo no processing, or minimal if at all, so that if there is any error in the processing, it can be fixed if not done on the original.
-
Data warehouse: A data warehouse reflects the global direction of how the data is finally used. It stores the data that has been processed and structured by a managed data model, often in a tabular form.
-
Datamart: This is where the data to be used by a particular business unit or geographical area is stored. It holds an aggregated and/or subpart data set. A good example is summarizing the key performance indicators (KPIs) for a specific line of business, and then visualizing it through a business intelligence (BI) tool. When frequent and regular updating of the data mart is required, it is worth spending time preparing this component after the warehouse step. However, if some data is needed only for one-time ad hoc data analysis, this can be skipped.
{kind=link}
Here are the key differences:
|
Component |
Purpose |
Built by |
Used by |
Data speed |
Maintenance cost |
|
Data lake |
Data storage Transaction-oriented |
1Data architect 3Data engineer |
2Data engineer 4Data scientist |
High, real-time |
Most expensive |
|
Data warehouse |
Data availability in a structured and managed format Analytics-oriented |
4Data architect 6Data engineer 7Data scientist |
5Data scientist Business expert |
Medium, regular/real-time |
Somewhat expensive |
|
Datamart |
Cherry-picking for specific business line usage Reporting-oriented |
8Data scientist Business expert |
Business expert |
Low, regular |
Least expensive |
What is the utility of separate components?
The purpose of different components is to cater to the requirements at different stages:
-
1Data lake: Maintain data as close to original as possible
-
2Data warehouse: Structure the data sets properly, put a proper maintenance plan in place for good manageability, clear ownership, and analytic-oriented database type
-
3Data mart: Suited to non-tech people who can easily access the final outputs of data journeys
-
Data Science Internships
The data extraction stage of the business, the data lake, building data models in the data warehouse, and establishing an extract-transform-load (ETL) pipeline fall under the purview of a data engineer. Data scientists, on the other hand, handle the stages from data extraction out of a data warehouse to building a data mart and creating value for business through further application. This, however, is just the ideal distribution, and in real life, the roles tend to overlap to some degree.
What tools are used for each component?
Given the differing purposes of each component, they require different tools to serve their respective purposes. Here are the details:
-
Data lake and data warehouse:
|
Data size |
Cloud/On-premise |
Vendor/OSS |
Tools |
|
PB/TB |
Cloud |
Vendor |
snowflake, BigQuery, Redshift, Amazon Athena, Azure Synapse Analytics, Treasure Data, Amazon S3 |
|
On-premise |
Teradata |
||
|
OSS |
Hadoop (HDFS, Hive, Presto), ClickHouse |
||
|
100s of MBs |
RDBMS, ELK Stack |
||
|
10s of MBs |
Microsoft Excel, Google Sheets |
||
-
ETL tools: The ETL process comes into the picture once the data in the data lake is to be processed for the data warehouse. Due to real-time arrival, event-driven messaging tools are preferred.
Batch/Streaming |
Cloud/On-premise |
Command/GUI |
Tools |
|
Batch |
On-premise |
Command |
Embulk |
|
GUI |
ASTERIA WARP, Alteryx, CDataSync, Information PowerCenter, Talend Platform |
||
|
Vendor |
Command |
AWS Glue, Databricks |
|
|
GUI |
Trocco, Reckoner, Azure Data Factory |
||
|
Streaming |
On-premise |
Fluentd, Apache Kafka, Logstash, Apache Storm |
|
|
Vendor |
Amazon Kinesis, AWS SNS + SQS + Lambda, Google Cloud Pub/Sub + Cloud Functions, Azure Stream Analytics |
||
|
Both |
On-premise |
Apache Spark, Apache Beam, SQL, Python, Java, Scala, Go, awk |
|
|
Vendor |
Cloud Dataflow |
||
-
Workflow engine: This manages the process of pipelining the data. Its uses include using a flow chart to visualize the stage of progress of a process, or triggering automatic retries when there are errors. Common options here include Apache Airflow, Luigi, Digdag, Azkaban, Jenkins, and Rundeck. Data architecture
-
Data mart or BI tools: The choice here depends on the business context, familiarity, aggregated data size, and the warehouse solution currently in use, among other considerations.
Type |
Tools |
|
Payment-based |
Tableau, Looker, Qlik, ThoughtSpot, Domo, Microsoft Power BI |
|
Free |
Redash, Metabase, Kibana, Grafana, Microsoft Power BI, Google DataStudio |
|
For use by anyone |
Microsoft, Google Sheets |